The story is always the same. A data team or a startup decides they need structured data from a handful of websites. Someone on the engineering team says, “I can build that in a weekend.” And they can - a basic scraper really does take a weekend. But production scraping is not a weekend project. It is an ongoing infrastructure commitment that quietly grows into a significant operational cost that most organisations only calculate honestly in hindsight.
By month three, the weekend scraper is breaking every time a target site pushes a layout update. By month six, there's a proxy bill no one budgeted for. By month twelve, your best engineers are spending 20–30% of their time keeping scrapers alive rather than building the thing your company actually does. And the data still isn't as reliable as you need it to be.
This is not an edge case. It is the standard trajectory of in-house scraping projects across companies of every size. The build vs buy question in web scraping is not primarily a technical question - it is a total cost of ownership question. And when you calculate TCO honestly, including the hidden costs most teams miss, the answer is clear for the majority of organisations: managed service wins on cost, speed, and reliability.
This guide gives you the numbers to make that calculation honestly - the real costs of building in-house, the real costs of managed service, and a clear framework for the specific situations where building actually does make sense.
It starts with a legitimate business need. You need competitor pricing data, or property listings from 20 portals, or job postings across 50 sites, or government contract announcements from SAM.gov and TED EU. Someone on your team estimates the work, builds a scraper, and it works. You get your data. Problem solved.
Then three weeks later the target site pushes an update and the scraper silently starts returning empty results. No one notices for four days because there's no monitoring. When you do notice, the engineer who built it is in the middle of something else and it takes two days to triage. The site changed its CSS class names and the selectors need updating. That's two hours of work. Fine - still manageable.
But then it happens again. And again. The site starts returning CAPTCHAs after 200 requests. You need a proxy provider now - another vendor, another monthly invoice, another configuration layer. The scraper needs to rotate user agents and headers or it gets blocked after 50 requests on a different site. You add that logic. Now you have a scraper that's complex enough that only one engineer on the team fully understands it.
That engineer leaves. You spend three weeks onboarding a replacement and discovering all the undocumented edge cases. One of your target sites moves to JavaScript rendering. Your current scraper can't handle it - you need a headless browser. You deploy Playwright. Cloud compute costs jump. The scraper still breaks when the site updates its React components. You're now managing a distributed scraping infrastructure that requires continuous attention from senior engineers.
This is the in-house scraping trap. The entry cost looks small. The ongoing cost compounds invisibly until you try to calculate it honestly.
Most cost estimates for in-house scraping miss the majority of the actual expense. They count initial development and maybe infrastructure, but they miss the ongoing operational cost that makes in-house consistently more expensive than the sticker price suggests.
The number that changes the conversation is usually the fully-loaded engineer cost. A $120K base salary engineer has a fully-loaded cost of $150K–$170K annually once payroll taxes, benefits, tooling, and overhead are included. If you are using two engineers for a scraping project - common once scale and maintenance requirements kick in - you are already at $300K+ before a single proxy or server is paid for.
Most teams don't account for this because the engineers were already on payroll doing other things. But engineering time is your most expensive and scarce resource. Every hour an engineer spends maintaining scrapers is an hour not spent on your core product. That opportunity cost is real even when it doesn't show up as a line item.
If there is one number that changes how most teams think about this decision, it is this: 20–40% of initial scraper development time is needed every year just for maintenance. Not to add new functionality. Just to keep existing scrapers working as target sites change.
The maintenance burden accumulates because websites change constantly. 72% of high-traffic websites change their structure regularly - that's the selector logic your scraper relies on. Major e-commerce sites update their product page structure to optimise conversion rates. News sites redesign their article layouts. Job boards change how they paginate results. Government procurement portals update their search interfaces. Every one of these changes can silently break a scraper - and if you're running 10, 20, or 50 scrapers, you are dealing with multiple breakages per week.
There's also the pagination problem, the rate limiting problem, and the redirect problem. A site that previously served paginated results at a predictable URL pattern switches to infinite scroll. A site that allowed 1,000 requests per hour drops its threshold to 200. A site migrates from HTTP to HTTPS and your scraper follows an old redirect that now returns a captcha. None of these are large problems in isolation. Collectively, they consume a disproportionate amount of senior engineering attention - exactly the kind of work that doesn't make it into sprint planning because it's always urgent and never planned.
Tell us what data you need and what format works for your team. We'll configure extraction, run quality checks, and deliver a free sample dataset within 48 hours. No proxies, no infrastructure, no maintenance on your end.
Five years ago, rotating your user-agent string and adding a 2-second delay between requests was enough to scrape most sites reliably. Today, the anti-bot landscape is fundamentally different - and it is getting more aggressive every year.
The current generation of bot management platforms - Cloudflare Bot Management, Akamai Bot Manager, DataDome, PerimeterX - operate using machine learning models trained on hundreds of millions of real user sessions. They detect automation not just through IP reputation but through mouse movement patterns, timing between keystrokes, browser fingerprint anomalies, TLS handshake characteristics, and behavioural sequences across an entire session. 82% of automated traffic can now be blocked by advanced bot management systems - meaning a naive scraper fails on most protected targets before it even starts extracting data.
Staying ahead of these defences requires constant investment. Headless browser fingerprints need regular rotation as detection systems are updated. Residential proxy pools need to be refreshed as IPs get flagged. CAPTCHA solving logic needs updating as CAPTCHA providers introduce new challenge types. Browser automation libraries need patching as anti-bot vendors write specific detections for known Puppeteer and Playwright signatures.
This is not a one-time problem you solve and move on from. It is an ongoing technical arms race. For a specialist managed scraping firm it is a core competency - we have teams specifically focused on keeping up with anti-bot evolution across every major platform. For an in-house team whose actual job is building your product, it is an expensive distraction.
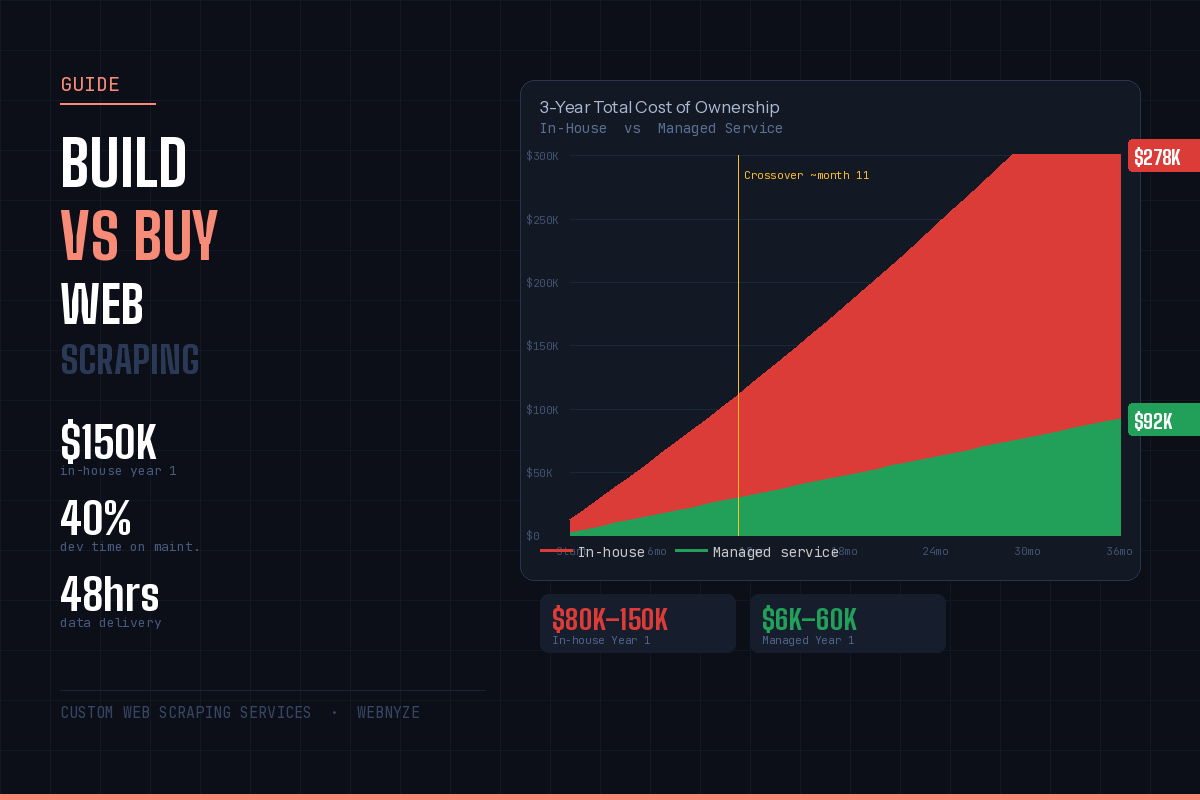
The total cost of ownership calculation over three years is where the in-house vs managed decision becomes undeniable for most organisations. Year 1 in-house looks painful but perhaps justifiable. Year 3 in-house, when maintenance burden has compounded and you're running multiple scrapers across multiple sites with a dedicated infrastructure, is consistently more expensive than even a well-scoped managed service contract - and delivers lower data quality.
The crossover point - when managed service has lower cumulative cost than in-house - typically occurs around months 8–14 for most mid-market scraping requirements. Before that crossover, in-house benefits from the fact that much of the engineering cost is already on payroll. After the crossover, every additional month of in-house scraping widens the gap.
The chart above shows one scenario. The numbers change based on your specific requirements - number of target sites, anti-bot complexity, data volume, and update frequency. But the shape of the curve is consistent: in-house front-loads cost, adds compounding maintenance overhead, and carries hidden opportunity costs. Managed service front-loads configuration, then runs at predictable cost with no maintenance on your end.
This is an honest assessment. Building in-house is the right answer for some organisations. Pretending otherwise would be both inaccurate and unhelpful.
If your entire business model is built on proprietary web data collection - you are a data company, not a company that uses data - then owning your extraction infrastructure is a strategic asset. The scraping is the product. No external service can match the depth of specialisation you need, and the competitive advantage genuinely comes from owning the capability rather than outsourcing it. Data companies like Similarweb, Semrush, or Crunchbase in their early stages built in-house because their proprietary collection methodology was their moat.
If your data needs require scraping billions of pages per month on an ongoing basis with highly specific validation logic, proprietary data structures, or integration requirements that no managed service can accommodate, the economics of in-house begin to favour a dedicated infrastructure investment. At extreme scale - tens of millions of records daily - the per-request costs of managed services can exceed the fixed cost of dedicated infrastructure. This threshold is higher than most teams assume. For most organisations, it is not reached.
Some data environments have regulatory, compliance, or security requirements that make any external data processing problematic. Financial services firms under specific regulatory frameworks, defence contractors handling sensitive procurement data, or healthcare organisations with strict data handling obligations may have valid reasons to keep all extraction in-house regardless of cost. This is a legitimate constraint - not a cost argument, but a compliance one. If this applies to you, the build vs buy question may be already answered by your legal and compliance team.
If none of these three situations applies to your organisation - and they don't apply to most companies that use web data - then in-house scraping is not a strategic asset. It is a commodity capability you are paying an above-market price to own. The question is not whether you can build it. You can. The question is whether building it is the best use of your engineering budget and your engineering team's time.
The managed service model works best when it is completely invisible to your team - you get data delivered in the format you need, on the schedule you need, and you never think about how it was collected. That is what we build. Here is what the process looks like in practice.
Tell us what data you need - the target sites, the fields that matter, the format you want, the update frequency, and how you want data delivered. We've handled everything from simple product price monitoring across 10 sites to complex multi-portal procurement intelligence aggregating 40+ government sources. If you already know exactly what you need, email hello@webnyze.com and we'll respond with a scoping proposal within 24 hours. No meeting required.
Before any contract is signed, we deliver a free sample dataset from your target sources. You validate the data quality, check the field coverage, confirm the format works for your team's workflow. Only once you're satisfied with the sample do we discuss ongoing pricing. This eliminates the biggest risk in any data service procurement - paying for data that doesn't actually meet your needs. The sample is your proof of capability before you commit.
Once approved, your pipeline runs on our infrastructure. We handle anti-bot bypass, proxy rotation, JavaScript rendering, rate limiting, CAPTCHA solving, data cleaning, deduplication, and schema validation. When a target site updates its structure and breaks extraction - which happens regularly - we detect it within hours and fix it without you filing a support ticket. Delivery to your S3 bucket, API endpoint, dashboard, or email digest continues on schedule. Your team sees clean data. We see the maintenance.
For clients on Managed Scraping and Custom Dashboard plans, we provide full source code, documentation, and deployment guides. The code is yours. If you ever want to bring the infrastructure in-house, you can - with a working, documented codebase rather than the usual legacy tangle of undocumented scrapers that get inherited when an engineer leaves. We also offer training handoffs where our engineers walk your team through the architecture. No vendor lock-in by design.
If you are genuinely evaluating this decision for your organisation, here are the five questions that will get you to the right answer faster than any feature comparison.
| Scenario | In-House | Managed Service | Verdict |
|---|---|---|---|
| One-time data pull, known structure, simple site | Quick to build, low ongoing cost | May be overkill for one-off | Consider in-house |
| Ongoing daily monitoring, 5–50 target sites | Maintenance burden grows fast | Predictable cost, zero maintenance | Managed wins clearly |
| Protected sites (Amazon, LinkedIn, Zillow, etc.) | Requires specialist anti-bot investment | Handled by provider as standard | Managed wins clearly |
| Multi-language portals (EU, APAC procurement) | Language normalisation is hard | Provider handles normalisation | Managed wins clearly |
| Scraping is core to your product / IP | Strategic control, proprietary methods | Less relevant when scraping is the product | In-house justified |
| Time-sensitive - need data in days not months | Weeks to months to production | Data delivered in 48 hours | Managed wins clearly |
| Infrequent scraping, unpredictable volumes | Fixed infrastructure cost even when idle | Pay for what you use | Managed wins clearly |
| Billions of pages/month, stable targets, mature team | Scale can justify infrastructure investment | Per-request costs become significant | Evaluate case-by-case |
Question 1: Is scraping your core product, or a means to an end? If you sell data, build. If you use data to make better decisions, buy.
Question 2: How often do your target sites change? If your targets are stable, well-documented APIs with no anti-bot measures and predictable structure - they exist, but they are rare - in-house is lower maintenance than average. If your targets are major consumer websites, managed wins on maintenance alone.
Question 3: What is your team's time actually worth? At $150/hour fully-loaded, 10 hours per week on scraping maintenance costs $78,000 per year. That's the opportunity cost of not building your core product. Does your scraping data generate more than $78,000 in value? Usually yes. But managed service generates the same data for less than $78,000 and frees that engineering time for product work.
Question 4: When do you need the data? If the answer is "in days not months," managed service is the only realistic option. Production-grade in-house scraping takes 2–3 months to build correctly. Free sample data from Webnyze is 48 hours.
Question 5: What happens when it breaks at 2am on a Sunday? With in-house scraping, your on-call engineer handles it. With managed service, we handle it. This is not a minor point - it is the thing that makes engineering teams want to move away from in-house scraping more than any other factor.
No proxies to set up. No scrapers to maintain. No engineers pulled off core product work. Describe your data requirements and we'll deliver a free sample dataset within 48 hours - no meeting required, no credit card, no commitment until you're satisfied with the data quality.
Know exactly what you need? Email us directly at hello@webnyze.com with your requirements.
Tell us what you need to scrape. We'll deliver a free sample dataset within 48 hours - no commitment, no credit card.