Government procurement is a massive market — the US federal government alone awards over $700 billion in contracts annually. For businesses chasing these opportunities, the challenge isn't a lack of tenders. It's finding the right ones before deadlines pass. Procurement data is scattered across dozens of portals, each with its own format, search interface, and update schedule.
We've built tender intelligence systems that consolidate opportunities from multiple portals into a single, searchable dashboard with automated alerts. Here's how it works.
The Problem with Manual Tender Monitoring
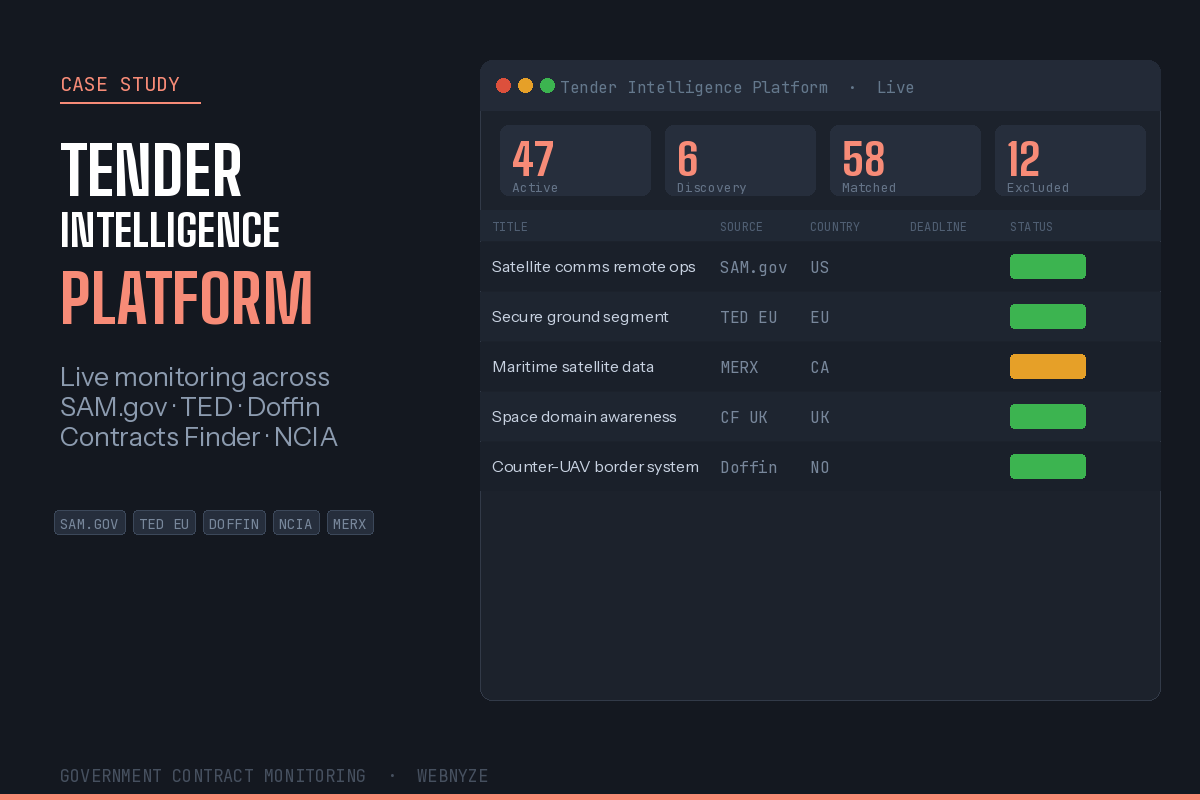
Most procurement teams rely on manual searches across portals like SAM.gov (US), TED/eTendering (EU), Contracts Finder (UK), MERX (Canada), and GeBIZ (Singapore). This approach has serious limitations:
- Time-intensive: Checking 5–10 portals daily takes hours and is error-prone
- Missed deadlines: Tenders expire quickly — some have 7–10 day response windows
- Inconsistent formats: Each portal structures data differently, making comparison difficult
- No historical analysis: Without archiving, you can't spot trends or recurring opportunities
Architecture of a Tender Scraping Pipeline
A production-grade tender intelligence system has four layers:
1. Data Collection Layer
Scrapy spiders are configured for each procurement portal. The key challenge is that many government sites use server-side rendering with pagination, AJAX-loaded content, or session-based authentication. We handle this with:
- Headless browser integration (Playwright) for JavaScript-heavy portals
- Session management for portals requiring login or cookie-based navigation
- Incremental crawling — only fetching new or updated listings since the last run
- Retry logic with exponential backoff for government sites with spotty uptime
2. Data Normalization
Raw tender data from different portals comes in wildly different formats. Our pipeline normalizes everything into a consistent schema:
- Title and description: Cleaned and standardized text
- Classification codes: NAICS (US), CPV (EU), UNSPSC mapped to a common taxonomy
- Value ranges: Converted to a single currency with daily exchange rates
- Dates: Publish date, submission deadline, and contract start date in ISO format
- Agency details: Issuing authority, contact information, and location
3. Matching and Scoring
Not every tender is relevant. We implement a multi-factor scoring system:
- Keyword matching: TF-IDF weighted keyword search against user-defined profiles
- Code matching: NAICS/CPV code overlap with the company's registered capabilities
- Value filtering: Minimum and maximum contract value thresholds
- Geographic relevance: Region and country filters
- Historical win rate: Boosting agencies where similar contracts were previously won
4. Delivery and Alerting
Matched tenders are delivered through multiple channels:
- Web dashboard: Filterable table with saved searches, notes, and team assignments
- Email digests: Daily or weekly summary of new matches
- Slack/Teams notifications: Instant alerts for high-priority tenders
- API endpoint: JSON feed for integration with existing CRM or bid management tools
Real-World Numbers
A typical deployment monitors 8–12 procurement portals and processes 2,000–5,000 new listings per day. After scoring and filtering, this usually narrows down to 20–50 relevant opportunities per client profile. The system runs on a schedule — most portals are crawled every 4–6 hours, with high-priority sources checked hourly.
Key Technical Challenges
- Portal redesigns: Government websites change layouts without notice. We use CSS selector fallback chains and automated breakage detection to handle this
- Rate limiting: Government servers often can't handle aggressive crawling. We use respectful crawl delays and distributed scheduling
- Document extraction: Many tenders link to PDF or DOCX attachments. We extract text from these using Apache Tika and feed it into the matching pipeline
- Deduplication: The same tender sometimes appears on multiple portals. We use fuzzy matching on title + agency + value to merge duplicates
Getting Started
If your team spends more than a few hours per week searching for tenders manually, a scraping-based intelligence platform can pay for itself within the first month. The ROI comes from two places: time savings for your bid team, and catching opportunities you would have otherwise missed.
We build these systems as turnkey solutions — you tell us which portals, keywords, and codes matter, and we handle the rest. Get in touch to discuss your procurement intelligence needs.